Deriva da tutte le unioni della magica 10° verifica e i collegamenti dei suoi particolari sono quelli iniziali:"Honors TPJ" e "Natural Author".
Il Caso ha voluto che inserissi anche Natural Magic come nome dell'11° verifica e insieme ad esse,esiste anche la "Natural Search" nelle Top Page Joy:)
Quindi il termine "Naturale" è parte integrante dei contenuti stessi e l'immagine sopra diventa la sua evidenza oggettiva e la prima unione sono i Keywords Stuffing della pagina A+ sotto e il passaggio del plagio.
Prima di sistemare l'unione effettiva,cito il contesto dell'immagine,ed è un servizio di Google Cloud attarverso il suo AI Machine Learning e "prevede anche dei costi".
Puo avere varie applicazioni nei Text,pero' ha "una base comune" ed è gratuita ed è ilsenso stesso di "Natural Language" e non riguarda il "Detect" e cioe' la lingua madre in cui sono scritti i contenuti,ma gli "eventuali strumenti automatici per crearli".
Cioe' il Natural Language è in realta' la sezione piu' importante del Rank by Brain e la sua versione gratuita è gia' nei reports degli Engine.

 L'immagine e il passaggio evidenziato sopra,derivano dalla prima pubblicazione degli Anchor Text
Al suo interno esistono i collegamenti delle altre 2 e sempre nei loro contenuti,sono sistemati degli esempi,uniti al "Markov Chains",ed è una delle "catene piu' note",per creare contenuti automatici (anche il Blockchain deriva da queste posizioni).
La migliore risposta è nella sezione evidenziata in blu,attraverso 1 solo termine,da parte del Search Console di Google:Crazy è la qualifica del Markov Chain e Big G,ha utiklizzato solo un altro termine caustico in tanti anni,ed è il "Run by Idiots" e il riferimento sono tutti i Link Schemes:)
💢
Il passaggio sotto deriva dal 7° RF 6D
💢
by sequenza" e naturalmente,le prime evidenze sono le risistemazioni,solo perche' sono i maggiori in dimensioni:)
L'immagine e il passaggio evidenziato sopra,derivano dalla prima pubblicazione degli Anchor Text
Al suo interno esistono i collegamenti delle altre 2 e sempre nei loro contenuti,sono sistemati degli esempi,uniti al "Markov Chains",ed è una delle "catene piu' note",per creare contenuti automatici (anche il Blockchain deriva da queste posizioni).
La migliore risposta è nella sezione evidenziata in blu,attraverso 1 solo termine,da parte del Search Console di Google:Crazy è la qualifica del Markov Chain e Big G,ha utiklizzato solo un altro termine caustico in tanti anni,ed è il "Run by Idiots" e il riferimento sono tutti i Link Schemes:)
💢
Il passaggio sotto deriva dal 7° RF 6D
💢
by sequenza" e naturalmente,le prime evidenze sono le risistemazioni,solo perche' sono i maggiori in dimensioni:)
 Il Natural language è la parte mancante dei Common Content e riguarda il Contesto Globale e il riferimento è alla naturalita' stessa dei contenuti,nel senso operativo:)
La prima sistemazione è nel precedente 6° RF della 6D e sara' inserito in qualsiasi RF successivo,perche' rappresenta la migliore unione con gli Index stessi,semplicemente con la sua presenza:) (la sua eventuale assenza,è il primo motivo dei De-Index).
Questo è il senso concreto del Natural Language
La posizione originale è all'interno della prima pubblicazione dedicata agli Anchor Text e tra i tanti collegamenti presenti,esiste anche quello per Markov Chain,ed è solo "la catena o schema" piu' nota,in senso negativo,naturalmente!:)
Il Natural language è la parte mancante dei Common Content e riguarda il Contesto Globale e il riferimento è alla naturalita' stessa dei contenuti,nel senso operativo:)
La prima sistemazione è nel precedente 6° RF della 6D e sara' inserito in qualsiasi RF successivo,perche' rappresenta la migliore unione con gli Index stessi,semplicemente con la sua presenza:) (la sua eventuale assenza,è il primo motivo dei De-Index).
Questo è il senso concreto del Natural Language
La posizione originale è all'interno della prima pubblicazione dedicata agli Anchor Text e tra i tanti collegamenti presenti,esiste anche quello per Markov Chain,ed è solo "la catena o schema" piu' nota,in senso negativo,naturalmente!:)
 Questa è "la parte pratica" del vero interesse per il Markov Chain
Questa è "la parte pratica" del vero interesse per il Markov Chain
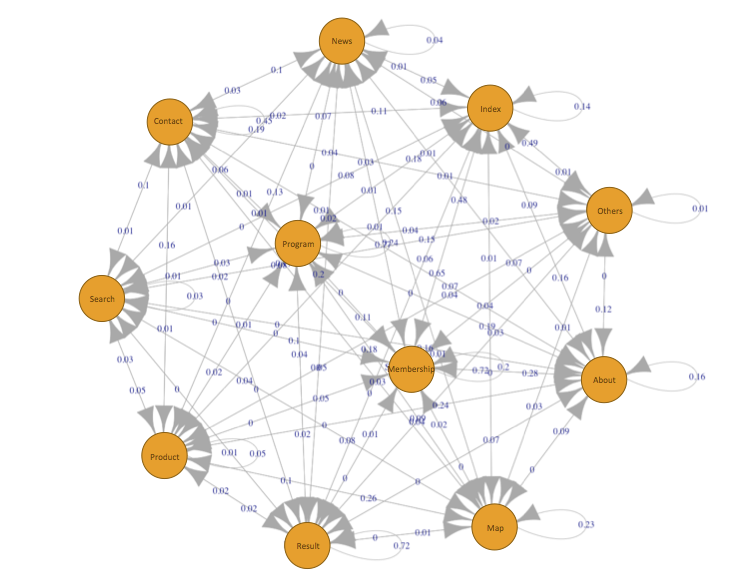 Questa è solo la posizione iniziale del Markov Chain e alimentano "tutti schemi reciproci",senza nessun valore reale,tranne ovviamente,per chi "prova ad abusarne":)
💢
Il passaggio sotto è tratto dalla pubblicazione che ha anticipato la 12° verifica
💢
I domini IBM ne sono "una miriade" e quindi figurarsi cosa sono il numero dei suoi subdomini e tra le tante possibilita',ne è uscito 1 solo!:)
Comunque,non è "uno qualsiasi",perche' "Developer.IBM.COM" è la punta di diamante negli sviluppi di IBM stessa:
Questa è solo la posizione iniziale del Markov Chain e alimentano "tutti schemi reciproci",senza nessun valore reale,tranne ovviamente,per chi "prova ad abusarne":)
💢
Il passaggio sotto è tratto dalla pubblicazione che ha anticipato la 12° verifica
💢
I domini IBM ne sono "una miriade" e quindi figurarsi cosa sono il numero dei suoi subdomini e tra le tante possibilita',ne è uscito 1 solo!:)
Comunque,non è "uno qualsiasi",perche' "Developer.IBM.COM" è la punta di diamante negli sviluppi di IBM stessa:
 la pubblicazione è del 25 giugno 2019:)
Insieme al Natural language è possibile inserire l'immagine in ogni RF successivo,perche' contiene il senso pratico della prima immagine di questa pubblicazione:
"King of Kings" ha come riferimento i Content e non potrebbe essere altrimenti,perche' è nato dalla prima verifica in assoluto dei TPJ Content Level e la posizione sopra,espreime il ruolo dei Contest e sono molto importanti,pero' solo dopo il "Trusted IoT",ed è la "traduzione operativa" dei Content stessi:) (con gli schemi o catene di ogni genere non è possibile avere " nessun Match Intent o Semantic" e di conseguenza non hanno nessun valore i contenuti:)
💢
Il passaggio sotto deriva dalla pubblicazione che ha anticipato il primo "FGL Star Unique Content"
💢
la pubblicazione è del 25 giugno 2019:)
Insieme al Natural language è possibile inserire l'immagine in ogni RF successivo,perche' contiene il senso pratico della prima immagine di questa pubblicazione:
"King of Kings" ha come riferimento i Content e non potrebbe essere altrimenti,perche' è nato dalla prima verifica in assoluto dei TPJ Content Level e la posizione sopra,espreime il ruolo dei Contest e sono molto importanti,pero' solo dopo il "Trusted IoT",ed è la "traduzione operativa" dei Content stessi:) (con gli schemi o catene di ogni genere non è possibile avere " nessun Match Intent o Semantic" e di conseguenza non hanno nessun valore i contenuti:)
💢
Il passaggio sotto deriva dalla pubblicazione che ha anticipato il primo "FGL Star Unique Content"
💢
 Per il momento inizio da questa posizione,ed è molto semplice,perche' è il linguaggio naturale effettivo.
qui esiste una traduzione
Cioe' non occorre preoccuparsi "della lingua utilizzata",perche' gli Engine la comprendono benissimo!:)
Proprio quest'ultimo punto "è la vera preoccupazione",perche' la comprensione è reale e altrettanto lo sono le posizioni globali successive,tramite le rilevanze e naturalmente,sono molto diverse ledifficolta',in base alle lingue.
La vera "Naturalita' per gli Engine" non è la lingua utilizzata,ma gli strumenti per creare i contenuti e quindi,i peggiori alleati,sono proprio "i software delle correzioni",perche' sono in realta',il primo livello degli strumenti automatici (è meglio fare degli errori di sintassi e grammaticali e saranno gli Engine stessi a correggerli:).
Il problema delle lingue,non riguarda la loro comprensione da parte degli Engine,ma è la rilevanza globale,la vera difficolta' :)
Per il momento inizio da questa posizione,ed è molto semplice,perche' è il linguaggio naturale effettivo.
qui esiste una traduzione
Cioe' non occorre preoccuparsi "della lingua utilizzata",perche' gli Engine la comprendono benissimo!:)
Proprio quest'ultimo punto "è la vera preoccupazione",perche' la comprensione è reale e altrettanto lo sono le posizioni globali successive,tramite le rilevanze e naturalmente,sono molto diverse ledifficolta',in base alle lingue.
La vera "Naturalita' per gli Engine" non è la lingua utilizzata,ma gli strumenti per creare i contenuti e quindi,i peggiori alleati,sono proprio "i software delle correzioni",perche' sono in realta',il primo livello degli strumenti automatici (è meglio fare degli errori di sintassi e grammaticali e saranno gli Engine stessi a correggerli:).
Il problema delle lingue,non riguarda la loro comprensione da parte degli Engine,ma è la rilevanza globale,la vera difficolta' :)
 L'immagine sopra appartiene "a un seo molto conosciuto" e nella stessa posizione è sistemata anche la sezione precedente.
La "naturalita' del linguaggio" ha come riferimento "le parole effettive e comuni" utilizzate in qualsiasi lingua.
Sono sistemate "le sintassi e gli errori grammaticali" nel primo punto e a seguire,è presente l'unione di "Sentiment Content".
Sono entrambi importanti,pero' non è questa la naturalita' effettiva dei Content:nel primo caso,sono gli Engine stessi a correggere gli eventuali errori e quindi,i termini sistemati in quella posizione non avranno rilevanza,pero' saranno presenti lo stesso.
Il secondo punto,ha invece un esempio diretto e sara' molto utile anche in questa posizione,ed è all'interno di Contest Absolute.
Esiste proprio il "Sentiment Content" e la sua funzione è unita alla semantic search e l'unione con questa posizione,è il suo passaggio finale e cioe' i reports sono validi,solo se esiste lo Status Code 200:)
In quel caso lo "strumento si è auto-limitato",perche' le stesse condizioni sono valide per ogni posizione negativa e la prima unione,è nell'immagine del Copied Content Quality Archive.
Il "Confidential Level" è servito per evidenziare il contesto complessivo e poi,esiste la posizione oggettiva dello strumento,ed è sempre all'interno degli Engine,secondo l'altissima percentuale sistemata sopra,pero' anch'esso ha dei limiti e non derivano "dalla naturalita' del linguaggio",ma dagli strumenti utilizzati per creare i contenuti:)
Ho inserito questo passaggio,perche' sara' protagonista anche nella pubblicazione effettiva di "FGL Star Unique Content" e nasce proprio dai Common Content,per una ragione molto semplice,perche' i gradi della leggibilita',hanno il riferimento complessivo di ogni pubblicazione,pero' non possiede i suoi "contenuti originali":)
Il senso è molto semplice,perche' i termini inseriti possono anche appartenere ad altre pubblicazioni dello stesso dominio e quindi,anche se avessero dei gradi ottimi,la loro efficacia sara' sempre relativa!
A maggior ragione,la stessa posizione esiste nel contesto globale online,ad iniziare dalle posizioni descritte per Sentiment Content,attraverso lo Status Code.
L'immagine sopra appartiene "a un seo molto conosciuto" e nella stessa posizione è sistemata anche la sezione precedente.
La "naturalita' del linguaggio" ha come riferimento "le parole effettive e comuni" utilizzate in qualsiasi lingua.
Sono sistemate "le sintassi e gli errori grammaticali" nel primo punto e a seguire,è presente l'unione di "Sentiment Content".
Sono entrambi importanti,pero' non è questa la naturalita' effettiva dei Content:nel primo caso,sono gli Engine stessi a correggere gli eventuali errori e quindi,i termini sistemati in quella posizione non avranno rilevanza,pero' saranno presenti lo stesso.
Il secondo punto,ha invece un esempio diretto e sara' molto utile anche in questa posizione,ed è all'interno di Contest Absolute.
Esiste proprio il "Sentiment Content" e la sua funzione è unita alla semantic search e l'unione con questa posizione,è il suo passaggio finale e cioe' i reports sono validi,solo se esiste lo Status Code 200:)
In quel caso lo "strumento si è auto-limitato",perche' le stesse condizioni sono valide per ogni posizione negativa e la prima unione,è nell'immagine del Copied Content Quality Archive.
Il "Confidential Level" è servito per evidenziare il contesto complessivo e poi,esiste la posizione oggettiva dello strumento,ed è sempre all'interno degli Engine,secondo l'altissima percentuale sistemata sopra,pero' anch'esso ha dei limiti e non derivano "dalla naturalita' del linguaggio",ma dagli strumenti utilizzati per creare i contenuti:)
Ho inserito questo passaggio,perche' sara' protagonista anche nella pubblicazione effettiva di "FGL Star Unique Content" e nasce proprio dai Common Content,per una ragione molto semplice,perche' i gradi della leggibilita',hanno il riferimento complessivo di ogni pubblicazione,pero' non possiede i suoi "contenuti originali":)
Il senso è molto semplice,perche' i termini inseriti possono anche appartenere ad altre pubblicazioni dello stesso dominio e quindi,anche se avessero dei gradi ottimi,la loro efficacia sara' sempre relativa!
A maggior ragione,la stessa posizione esiste nel contesto globale online,ad iniziare dalle posizioni descritte per Sentiment Content,attraverso lo Status Code.
 Questa è una delle posizioni per indicare "la naturalita' effettiva del linguaggio" e i suoi contenuti sono tutti importanti,pero' quelli evidenziati lo sono un po' di piu'!:)
La prima evidenza è il fatto che i contenuti,riguardano qualsiasi linguaggio,mentre è molto differente il senso del termine "Similar",semplicemente perche' non esiste operativamente!:)
Questa è una delle posizioni per indicare "la naturalita' effettiva del linguaggio" e i suoi contenuti sono tutti importanti,pero' quelli evidenziati lo sono un po' di piu'!:)
La prima evidenza è il fatto che i contenuti,riguardano qualsiasi linguaggio,mentre è molto differente il senso del termine "Similar",semplicemente perche' non esiste operativamente!:)
 I "Duplicate Url" hanno come riferimento 1 sola pubblicazione a cui sono uniti i contenuti e questo è il senso del canonical.
Quindi comprendono tutti i contenuti di qualsiasi pubblicazione e "il similar" non potra' proprio esistere e questo è l'aspetto naturale effettivo:)
I "Duplicate Url" hanno come riferimento 1 sola pubblicazione a cui sono uniti i contenuti e questo è il senso del canonical.
Quindi comprendono tutti i contenuti di qualsiasi pubblicazione e "il similar" non potra' proprio esistere e questo è l'aspetto naturale effettivo:)
 in questa posizione ho inserito la protagonista del 9° RF della 6D:)
la certificazione della sua naturalita' è gia' nel numero di omissioni,perche' non esiste nessuno strumento artificiale,che "è programmato per farlo":)
in questa posizione ho inserito la protagonista del 9° RF della 6D:)
la certificazione della sua naturalita' è gia' nel numero di omissioni,perche' non esiste nessuno strumento artificiale,che "è programmato per farlo":)
 Questo è un altro aspetto dei duplicati e insieme al precedente,confluiscono nei broken Links ed è identico al suo "ruolo ufficiale",ed è l'assenza dei contenuti,a prescindere dal fatto che esistano.
Questa è la naturalita' effettiva e l'ho sistemata,perche' sara' protagonista nella pubblicazione del primo FGL Star Unique Content.
💢
Il passaggio sotto è tratto da "FGL Star Unique Content ONE"
💢
Tra i vari passaggi della pubblicazione che ha anticipato questa verifica,esiste anche l'immagine sopra e anch'essa è unita al "Natural Language" e dai pochi contenuti inseriti si comprende molto bene,quali sono le posizioni reali per "il linguaggio naturale":)
La parte evidenziata ha il contesto diretto anche con i contenuti delle verifiche e di qualsiasi altra posizione online,perche' tutti le lingue sono "coinvolte in un unica posizione" e questo è normale,perche' le unicita' sono sempre globali.
Comunque esiste,nella realta',una differenza notevole rispetto ai contenuti sopra e deriva da "Similar",perche' operativamente non esiste:)
Questa è l'unione nei Duplicate Url "dei similar" e cioe' "non esiste una zona franca",unita "alla similarita'",ma sono tutte associate ai duplicati.
A maggior ragione,il "similar" è assente nei termini effettivi e possono determinare i "duplicate links" e non sono "doppi collegamenti",ma sono i termini effettivi inseriti nei links,tramite duplicati o plagi di altri domini e anche in questo caso,non esiste "una zona franca" e cioe' non è presente nessuna "similarita'" tra i termini e quindi possono essere solo,duplicati o unici.
(solo per curiosita',posso aggiungere che il Support di Google sistemato è recente e per paradoso,una "similarita' esiste",ed è il Common Content e da oltre 1 anno,in maniera specifica è inserito nei duplicati:)
Questo è un altro aspetto dei duplicati e insieme al precedente,confluiscono nei broken Links ed è identico al suo "ruolo ufficiale",ed è l'assenza dei contenuti,a prescindere dal fatto che esistano.
Questa è la naturalita' effettiva e l'ho sistemata,perche' sara' protagonista nella pubblicazione del primo FGL Star Unique Content.
💢
Il passaggio sotto è tratto da "FGL Star Unique Content ONE"
💢
Tra i vari passaggi della pubblicazione che ha anticipato questa verifica,esiste anche l'immagine sopra e anch'essa è unita al "Natural Language" e dai pochi contenuti inseriti si comprende molto bene,quali sono le posizioni reali per "il linguaggio naturale":)
La parte evidenziata ha il contesto diretto anche con i contenuti delle verifiche e di qualsiasi altra posizione online,perche' tutti le lingue sono "coinvolte in un unica posizione" e questo è normale,perche' le unicita' sono sempre globali.
Comunque esiste,nella realta',una differenza notevole rispetto ai contenuti sopra e deriva da "Similar",perche' operativamente non esiste:)
Questa è l'unione nei Duplicate Url "dei similar" e cioe' "non esiste una zona franca",unita "alla similarita'",ma sono tutte associate ai duplicati.
A maggior ragione,il "similar" è assente nei termini effettivi e possono determinare i "duplicate links" e non sono "doppi collegamenti",ma sono i termini effettivi inseriti nei links,tramite duplicati o plagi di altri domini e anche in questo caso,non esiste "una zona franca" e cioe' non è presente nessuna "similarita'" tra i termini e quindi possono essere solo,duplicati o unici.
(solo per curiosita',posso aggiungere che il Support di Google sistemato è recente e per paradoso,una "similarita' esiste",ed è il Common Content e da oltre 1 anno,in maniera specifica è inserito nei duplicati:)
 questo è un esempio sempre per il senso reale del Natural Language
In questo caso non esistono strumenti automatici o software di correzione,ma sono "azioni volontarie",prevalentemente utilizzate dagli e-commerce,pero' sono presenti anche nelle altre categorie.
Sono delle sezioni (appended) aggiunte agli indirizzi e ufficialmente sono create per tracciare le operazioni degli utenti.
In genere,vengono utilizzate le migliori pubblicazioni e sono aggiunte altre pagine con il metodo sopra,ed è un operazione da "non copiare in tutti i sensi",perche' saranno tutte classificate nei duplicati ,compresi i contenuti pregiati:)
Adesso aggiungo altre posizioni,sempre per la "naturalita' del linguaggio" e l'unione è nell'evidenza di hreflang e cioe' sono tutti i contenuti in competizione,a prescindere dalle lingue e naturalmente esiste la differenza dei termini unici e quella appena aggiunta "della similarita'" e quest'ultima è solo teorica,perche' esistono solo 2 alternative possibili:) (possono esistere solo contenuti unici o duplicati)
questo è un esempio sempre per il senso reale del Natural Language
In questo caso non esistono strumenti automatici o software di correzione,ma sono "azioni volontarie",prevalentemente utilizzate dagli e-commerce,pero' sono presenti anche nelle altre categorie.
Sono delle sezioni (appended) aggiunte agli indirizzi e ufficialmente sono create per tracciare le operazioni degli utenti.
In genere,vengono utilizzate le migliori pubblicazioni e sono aggiunte altre pagine con il metodo sopra,ed è un operazione da "non copiare in tutti i sensi",perche' saranno tutte classificate nei duplicati ,compresi i contenuti pregiati:)
Adesso aggiungo altre posizioni,sempre per la "naturalita' del linguaggio" e l'unione è nell'evidenza di hreflang e cioe' sono tutti i contenuti in competizione,a prescindere dalle lingue e naturalmente esiste la differenza dei termini unici e quella appena aggiunta "della similarita'" e quest'ultima è solo teorica,perche' esistono solo 2 alternative possibili:) (possono esistere solo contenuti unici o duplicati)
 All'apparenza sembra un immagine "avulsa da questo contesto",mentre è esattamente l'opposto,ed è sufficente unirla al valore globale di qualsiasi contenuto e non occorre aggiungere altri dati,ma sono sufficenti i pochi contenuti dell'immagine,per avere la conferma dell'operativita' reale del natural Language.
Quello sistemato sopra è l'Automated Index e nella pubblicazione precedente esiste il collegamento con il suo contesto diretto e in questa posizione,è molto semplice creare l'unione,perche' la naturalita' è evidente subito e non esiste nessuna alternativa ad essa:)
Tra l'altro è solo 1 grado di riferimento e poi occorre "unire anche i rapporti degli altri" e quindi,la naturalita' è certa,perche' esiste solo l'alternativa degli Automated Content effettivi(solo dei software artificiali possono unire tutte le formule insieme per "creare dei content") pero', se fossero presenti loro,non esisterebbe proprio la pubblicazione!:)
All'apparenza sembra un immagine "avulsa da questo contesto",mentre è esattamente l'opposto,ed è sufficente unirla al valore globale di qualsiasi contenuto e non occorre aggiungere altri dati,ma sono sufficenti i pochi contenuti dell'immagine,per avere la conferma dell'operativita' reale del natural Language.
Quello sistemato sopra è l'Automated Index e nella pubblicazione precedente esiste il collegamento con il suo contesto diretto e in questa posizione,è molto semplice creare l'unione,perche' la naturalita' è evidente subito e non esiste nessuna alternativa ad essa:)
Tra l'altro è solo 1 grado di riferimento e poi occorre "unire anche i rapporti degli altri" e quindi,la naturalita' è certa,perche' esiste solo l'alternativa degli Automated Content effettivi(solo dei software artificiali possono unire tutte le formule insieme per "creare dei content") pero', se fossero presenti loro,non esisterebbe proprio la pubblicazione!:)

