La nuova pagina di Key TD Archive avra' la stessa funzione delle altre e cioe' rendera' facile i collegamenti ,con i contenuti specifici futuri,a cui è dedicata.I suoi elementi sono la Struttura Data ; gli Snippet ;le Sitemap e il loro insieme comprende qualsiasi categoria online e la loro sintesi è nell'altro elemento presente in questa pagina e cioe' il Business.Con questi elementi è facile l'unione con il nome della pagina :DON'T DECEIVE YOUR USERS:)
La nuova pagina di Key TD Archive avra' la stessa funzione delle altre e cioe' rendera' facile i collegamenti ,con i contenuti specifici futuri,a cui è dedicata.I suoi elementi sono la Struttura Data ; gli Snippet ;le Sitemap e il loro insieme comprende qualsiasi categoria online e la loro sintesi è nell'altro elemento presente in questa pagina e cioe' il Business.Con questi elementi è facile l'unione con il nome della pagina :DON'T DECEIVE YOUR USERS:)Prima di arrivare agli elementi ,occorre sistemare le basi e il"Friendly" è proprio indispensabile,ed "è un amicizia che non si puo recuperare":) (è sufficente seguire le guidelines sempre e l'amicizia è sicura:)
Questa è un altra posizione fantastica: "Occorre essere sicuri" che i Links verso i domini "siano naturali" e altrettanto quelli esterni,verso altri spazi:)
Questo "serve per mantenere l'amicizia" ,ed è una normale posizione e il suo aspetto fantastico,riguarda solo i domini individuali,perche' non esiste nessuna segnalazione e quindi solo i Content hanno fatto la differenza:)
E' sufficente leggere il primo periodo e contestualizzarlo ,attraverso gli "strumenti sofisticati" e nel Caso di Google lo sono realmente,applicati ai Match dei Text:)
E' un contesto meraviglioso peri Content individuali ,ed è sufficente leggere il primo periodo sopra e poi applicarlo ai Match dei contenuti,senza avere nessun Backlinks:)
In tutti gli RF (è possibile considerare anche il 73°,perche' esistono gia' i dati) e in tutti i Just Time,non esistono solo un numero ciclopico di Conflitti (sono i Match dei Text tramite i migliori strumenti in assoluto ) ,ma sono presenti contemporaneamente Oceani di Backlinks ,ed è sufficente aggiungere il 2° periodo (quello degli algoritmi) ,per comprendere una cosa semplice e cioe' tutti i links dei Match nei Text sono naturali,altrimenti non sarebbero presenti:)
Questa posizione,deriva dalla precedente e la distinzione tra INDEX e il loro Opposto ,nasce dai Text Match piu' sofisticati e lo sono realmente:) L'opposto agli Index è formato da tutte le posizioni Unnatural e quella dei Links ne è solo UNA!:)
Ovviamente esiste anche "l'aspetto naturale " dei De-Index e cioe' i Content possono anche appartenere ad altri domini:)
Anche questa è una posizione fantastica,ed è unita proprio al termine AVOID:)
Le descrizioni dei contenuti dell'immagine sono molto semplici:occorre fare attenzione a sistemare "solo liste di Keywords" ,perche' il dominio a cui appartengono verra' completamente ignorato.
Occorre fare anche attenzione "all'utilizzo di agenzie di ottimizzazione" ,perche' tante di esse "utilizzano deceptive tactics" e il risultato finale sara' il Banned dagli Index:)
Il termine AVOID è proprio perfetto in questa situazione:
questi pensieri "occorre averli prima di creare i contenuti" e in questo contesto "l'amicizia dura nel tempo":)
In tanti ottimizzatori,il termine AVOID "è interpretato all'opposto" e cioe' di "togliere posizioni negative" dopo aver creato i contenuti:)
La prima posizione ha come riferimento Don't DEcive Your Users:)
Quelli che pensano di utilizzare l'AVOID "a loro piacimento" ,sono i presuntuosi dei Deceive Users e la loro naturale posizione è nei Brain Stone:)
Il contesto originale del primo passaggio è qui
Nei Crowling Process esistono anche queste posizioni per gli INDEX e i contenuti applicati,hanno estensioni enciclopedice e quindi inserisco le parti essenziali:)
Nella realta',le Structured Data sono molto semplice,perche' rappresentano le posizioni Standard dei Content,in qualsiasi dominio e per rendere facile la posizione,ho scelto "i ruoli complessi":)
E' sufficente solo l'unione del primo e gli altri elementi presenti,rappresentano solo delle descrizioni,poco verificali,proprio per il ruolo Standard delle Strutture Data stesse:)
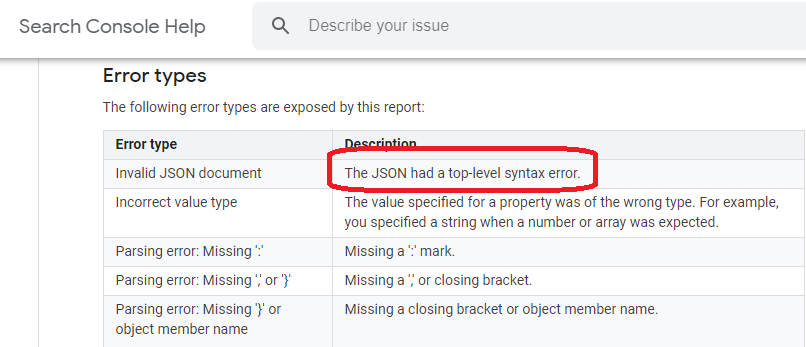
La meno verificabile,è nella prima posizione e sono gli Invalid Document di JSON,ed è solo uno dei Format Maggiori delle strutture data.
E' davvero "un ipotesi molto remota" che esistano degli Invalid Document,non solo perche' il software è tra i piu' sofisticati,ma sopratutto perche' fornisce delle "strutture standard"e quindi le probabilita' che esistano "degli errori di sintassi" di JSON,sono nulle!:)
Non esistono errori di sintassi nelle strutture data (ovviamente se sono presenti) ,ma sono sempre i Webmastres,a procurare i danni ,ed è il senso di Misleadings Markup (in maniera eufemistica si definiscono "FUORVIANTI":)
Questa è la divisione del Markup e quindi è facile anche l'unione con le Strutture Data e diventa molto semplice l'unione descritta a JUN 2020 e inizia con le posizioni di Google Facts e Google Patents,proprio attraverso "il Markup fuorviante":) Sono i falsi piu' semplici da scoprire,perche' se sono idioti con le strutture data (sono realizzate tutte in maniera Standard) e imbecilli con il Markup (le percentuali sono quelle sopra ) ,non possono fornire nessun valore reale,a parte l'idiozia di chi sceglie queste operazioni:)
Per gli strumenti dei rilevamenti di base non occorre "un grande impegno" per rilevare la presenza di Crawlwer o Bots,semplicemente perche' non hanno nessun codice Javascript e le selezioni iniziano dalle percentuali sopra del Markup e in pratica sono complete al 100% e quindi è sufficente vedere s esistono o meno i codici:)
L'unione di queste posizioni con la verifica dei contenuti interni dei domini,di OCT 2020, è molto semplice,perche' le "Strutture Data e il Markup" permettono la migliore comprensione dei contenuti ,in funzione della NATURALITA' dei Medesimi:) Nei dati delle verifiche è impossibile conoscrla per tutti i domini,tranne in quello individuale,perche' esistono 71 RF ed è gia' iniziato il K2 del Just Time e per essere presenti i loro dati,significa che i Crawling Process sono gia' avvenuti :)
Ho scelto di sistemarla perche' in alcuni reports esiste la sua presenza,mentre nell'immagine collegata sopra,è indicata l'attuale operativita' per le strutture data di Google.
Occorre aggiungere la cosa piu' banale,pero'è molto importante lo stesso, e cioe' le strutture data servono "per comprendere meglio i contenuti" e quindi è indispensabile che esista e naturalmente è presente anche il suo opposto e cioe' "la migliore comprensione" ,rende anche molto piu' elevata la possibilita' di avere dei Match e quindi di essere eliminati:)
Il fine ultimo di queste posizioni sono formati dagli "END of CODE" e sono i codici finali di qualsiasi contenuto del contesto online (periodo by periodo:) e sono essi a formare le Grid to Record e dai loro valori,nascono anche ui Crawling Process successivi.

Le descrizioni sono nel Natural Contest precedente,dedicato agli High learning italiani:)
Posso assicuarare che quando ho creato il passaggio,non conoscevo ancora le posizioni appena aggiunte ,ed è proprio la pagina di facebook dedicata alle Ads unite agli "articoli istantanei":)Oltre ai contenuti sistemati,esiste anche una logica,ed è unita ai valori reali enon sono le Ads,ma i contenuti e quindi è giusta la collocazione di Struttura Data e i contenuti della pubblicazione non possono essere uniti a nessuno snippet,semplicemente perche' non appartengono al dominio specifico e le descrizioni sono nel Brain Stone collegato sopra.Adesso aggiungo una cosa davvero curiosa e deriva sempre dalla pagina di "facebook dedicata alle Ads e agli articoli istantanei":)Sono descritti i particolari tecnici,sempre secondo loro (350 termini ad articolo istantaneo e sarebbe quasi l'inizio del Thin Content nella realta' del web:) e per rendere "piu' convincenti i loro dati",ovviamente rispetto ai loro utenti,hanno aggiunto le"proprie linee guida" e sono quelle di facebook e di instagram:)Esistono diverse pubblicazioni dedicate e una di esse è quiLa posizione è solo un esempio e la ricerca interna è valida per tutte le linee guida di facebook e non esiste 1 sola citazione per il copyright e il primo collegamento nasce proprio dalle Ads per "i contenuti istantanei":)
Addirittura,"nel regno degli schemi;dei farm links e likes" non esiste nemmeno 1 presenza per i backlinks e quindi è "pacifico" che siano false anche le linee guida che si sono dati a facebook e instagram:) (i termini piu' utilizzati riguardano la violenza e il crimine:)Il Contesto Originale del passaggio sopra è qui
 Oltre al collegamento dei Brain Stone,le Strutture Data hanno anche altre posizioni : sono nel 4° Natural Contest degli High Learning italiani ; sono ad OCT 2020 ; sono presenti anche nel 1° Just Time K2 e naturalmente sono anche nei contenuti della pagina A+ di questo 72° RF .Ovviamente le strutture data sono presenti ovunque e le sue Guidelines sono "molto semplici",perche' è sufficente seguire (sono gli unici "Followers raccomandabili davvero di seguire":) il primo periodo dell'immagine sopra:) (cioe' è indispensabile che la Struttura Data Esista:)Questa posizione è valida per qualsiasi categoria,ed è fondamentale per i contenuti che aggiungero' (categorie del Business online e Snippet Featured) e i dati che conterranno,saranno presenti in tutti gli RF e i Just Time futuri.Sono tante le posizioni sistemate e quindi ho scelto di creare una nuova pagina che le conterra' tutte ,ed è stato semplice scegliere il suo nome e sara' :"Don't Deceive Your Users":)La sistemazione sara' su Key TD Archive e diventera' molto facile comparare i contenuti che avra',perche' sranno completamente opposti a quelli dei Brain Stone e la loro idiozia inizia "dall'atto di superbia" e cioe' pensano di decidere i loro utenti:) La Superbia nasce dal fatto che non conoscono nulla del contesto globale e da questa posizione, pensano di scegliere gli utenti ,immaginando che siano davvero "solo una massa d'imbecilli":)Il contesto online ha invece svelato una realta' meravigliosa e cioe' l'intelligenza esiste (rappresenta il senso reale dello IoT:) ,ed è diffusissima (i dati degli INDEX della rete italiana sono un altro ottimo esempio:) e a unire queste posizioni ,esiste in apparenza un paradosso, perche' i "software opposti alla superbia" sono formati dagli AI (Artificial Inteligence) e in realta' è una posizione naturale ,perche' tutti gli AI , sono nati dal Natural Brain:)Le differenze restano quelle naturali: esistono sempre gli imbecilli e pensano che il contesto online sia "uguale a quello tradizionale" e quindi è possibile avere anche dei dati totalmente falsi ,utilizzando "varie scorciatoie" e presentarli "come dati veri":) (è il vero ruolo e posizione dei social e per questo motivo è lecito il termine applicato e cioe' Deceptive e Deprecated Intent:)Il contesto online,a differenza di quello tradizionale,è capace di separare gli imbecilli ,dall'intelligenza reale e solo quest'ultima ha possibilita' di esistere:)Per verificarlo,esiste la semplice ragione,ed è sufficente immaginare "la trasposizione operativa di coloro che immaginano di decidere gli utenti" ,ed è formata solo da schemi e non è possibile che "vinca nessuno" ,perche' si elideranno a vicenda :) (la ragione semplice deriva dal fatto che a queste condizioni,non esisterebbe nemmeno il contesto online:)Un esempio delle differenze è nell'immagine sotto:
Oltre al collegamento dei Brain Stone,le Strutture Data hanno anche altre posizioni : sono nel 4° Natural Contest degli High Learning italiani ; sono ad OCT 2020 ; sono presenti anche nel 1° Just Time K2 e naturalmente sono anche nei contenuti della pagina A+ di questo 72° RF .Ovviamente le strutture data sono presenti ovunque e le sue Guidelines sono "molto semplici",perche' è sufficente seguire (sono gli unici "Followers raccomandabili davvero di seguire":) il primo periodo dell'immagine sopra:) (cioe' è indispensabile che la Struttura Data Esista:)Questa posizione è valida per qualsiasi categoria,ed è fondamentale per i contenuti che aggiungero' (categorie del Business online e Snippet Featured) e i dati che conterranno,saranno presenti in tutti gli RF e i Just Time futuri.Sono tante le posizioni sistemate e quindi ho scelto di creare una nuova pagina che le conterra' tutte ,ed è stato semplice scegliere il suo nome e sara' :"Don't Deceive Your Users":)La sistemazione sara' su Key TD Archive e diventera' molto facile comparare i contenuti che avra',perche' sranno completamente opposti a quelli dei Brain Stone e la loro idiozia inizia "dall'atto di superbia" e cioe' pensano di decidere i loro utenti:) La Superbia nasce dal fatto che non conoscono nulla del contesto globale e da questa posizione, pensano di scegliere gli utenti ,immaginando che siano davvero "solo una massa d'imbecilli":)Il contesto online ha invece svelato una realta' meravigliosa e cioe' l'intelligenza esiste (rappresenta il senso reale dello IoT:) ,ed è diffusissima (i dati degli INDEX della rete italiana sono un altro ottimo esempio:) e a unire queste posizioni ,esiste in apparenza un paradosso, perche' i "software opposti alla superbia" sono formati dagli AI (Artificial Inteligence) e in realta' è una posizione naturale ,perche' tutti gli AI , sono nati dal Natural Brain:)Le differenze restano quelle naturali: esistono sempre gli imbecilli e pensano che il contesto online sia "uguale a quello tradizionale" e quindi è possibile avere anche dei dati totalmente falsi ,utilizzando "varie scorciatoie" e presentarli "come dati veri":) (è il vero ruolo e posizione dei social e per questo motivo è lecito il termine applicato e cioe' Deceptive e Deprecated Intent:)Il contesto online,a differenza di quello tradizionale,è capace di separare gli imbecilli ,dall'intelligenza reale e solo quest'ultima ha possibilita' di esistere:)Per verificarlo,esiste la semplice ragione,ed è sufficente immaginare "la trasposizione operativa di coloro che immaginano di decidere gli utenti" ,ed è formata solo da schemi e non è possibile che "vinca nessuno" ,perche' si elideranno a vicenda :) (la ragione semplice deriva dal fatto che a queste condizioni,non esisterebbe nemmeno il contesto online:)Un esempio delle differenze è nell'immagine sotto: Sono tutte posizioni importanti,pero' quelle evidenziate lo sono un po' di piu':)Inizia dal fatto piu' semplice e cioe' la Struttura Data non rappresenta il Main Content ,perche' l'applicazione riguarda 1 sola pubblicazione e le altre presenti in 1 dominio,potrebbero essere anche diverse.L'importanza deriva dal fatto che esista e la ragione è molto semplice,perche' è proprio la Struttura Data a fornire "la migliore comprensione dei Content" e ovviamente,non indica che sia presente il Main Content,pero' permette di verificarlo:) Se una pubblicazione "non fosse compresa" è impossibile compararla con le altre e di conseguenza non si avra' mai nessun Main Content e sara' inutile vedere se esiste il suo Copied:)Quindi,senza Struttura Data,non esistera' nemmeno la rilevanza dei Content e da essi, non avranno nessun valore ,qualsiasi dato dei rilevamenti di base.Questa posizione permette la verifica piu' sublime e sono gli oceani di tools presenti nel web , ed è sufficente scegliere quelli che si occupano di Keywords:) Occorre solo applicare il passaggio precedente ai loro dati e si avra' la verifica effettiva e non sara' quella dei dati,ma quella dei tools stessi:)Ne esistera' anche una diretta,perche' il prossimo Natural Contest,riguardera' gli spazi dedicati ai "rilevamenti di base"(il collegamento è nella sidebar attraverso il piccolo background) e non occorre nemmeno aspettare i dati,perche' nella pagina dei sistemi, esistono gia' 3 pubblicazioni dedicate agli spazi degli strumenti dei rilevamenti di base (sono esclusivamente quelli ufficiali) e attraverso loro,diventa moto facile l'unione dei passagi precedenti (è sufficente il contrappasso tra i dati dei rilevamenti di base e il valore effettivo dei loro contenuti diretti:)
Sono tutte posizioni importanti,pero' quelle evidenziate lo sono un po' di piu':)Inizia dal fatto piu' semplice e cioe' la Struttura Data non rappresenta il Main Content ,perche' l'applicazione riguarda 1 sola pubblicazione e le altre presenti in 1 dominio,potrebbero essere anche diverse.L'importanza deriva dal fatto che esista e la ragione è molto semplice,perche' è proprio la Struttura Data a fornire "la migliore comprensione dei Content" e ovviamente,non indica che sia presente il Main Content,pero' permette di verificarlo:) Se una pubblicazione "non fosse compresa" è impossibile compararla con le altre e di conseguenza non si avra' mai nessun Main Content e sara' inutile vedere se esiste il suo Copied:)Quindi,senza Struttura Data,non esistera' nemmeno la rilevanza dei Content e da essi, non avranno nessun valore ,qualsiasi dato dei rilevamenti di base.Questa posizione permette la verifica piu' sublime e sono gli oceani di tools presenti nel web , ed è sufficente scegliere quelli che si occupano di Keywords:) Occorre solo applicare il passaggio precedente ai loro dati e si avra' la verifica effettiva e non sara' quella dei dati,ma quella dei tools stessi:)Ne esistera' anche una diretta,perche' il prossimo Natural Contest,riguardera' gli spazi dedicati ai "rilevamenti di base"(il collegamento è nella sidebar attraverso il piccolo background) e non occorre nemmeno aspettare i dati,perche' nella pagina dei sistemi, esistono gia' 3 pubblicazioni dedicate agli spazi degli strumenti dei rilevamenti di base (sono esclusivamente quelli ufficiali) e attraverso loro,diventa moto facile l'unione dei passagi precedenti (è sufficente il contrappasso tra i dati dei rilevamenti di base e il valore effettivo dei loro contenuti diretti:) Anche questa posizione aiuta tantissimo a comprendere il nome che avra' la prossima pagina di Key TD Archive.Sono sempre le Guidelines della Struttura Data e inizia dalla cosa piu' semplice,ed è il valore dei "veri Followers":)E' indispensabile "seguire" le linee guida generali e sotto di essa,esiste la loro unica operativita' e cioe' i valori dei dati,possono avere 1 solo riferimento temporale ed è quello del Long Standing Webmasters Guidelines.E' il senso reale del secondo periodo (Provide up to date information) e cioe' il Rich Result (Struttura Data e Snippet) non puo essere unito "solo a una data sensibile" (il riferimento è a quella dei Crawling Process) ,ma deve avere il percorso temporale completo (è il senso reale di longer rilevant)qui è sistemata la pagina completa con le 3 sezioni sopra
Anche questa posizione aiuta tantissimo a comprendere il nome che avra' la prossima pagina di Key TD Archive.Sono sempre le Guidelines della Struttura Data e inizia dalla cosa piu' semplice,ed è il valore dei "veri Followers":)E' indispensabile "seguire" le linee guida generali e sotto di essa,esiste la loro unica operativita' e cioe' i valori dei dati,possono avere 1 solo riferimento temporale ed è quello del Long Standing Webmasters Guidelines.E' il senso reale del secondo periodo (Provide up to date information) e cioe' il Rich Result (Struttura Data e Snippet) non puo essere unito "solo a una data sensibile" (il riferimento è a quella dei Crawling Process) ,ma deve avere il percorso temporale completo (è il senso reale di longer rilevant)qui è sistemata la pagina completa con le 3 sezioni sopra
L'applicazione diretta dei passaggi precedenti , è unita ai contenuti dell'immagine sopra.Inizia dal contesto piu' semplice e cioe' anche il Businness ,attraverso le sue categorie, è unito alle General Guidelines.La prima evidenza è,naturalmente ironica , perche' nelle linee guida piu' importanti al mondo ,non esiste "l'onesta condizionata":)(YOU SHOULD BE UPFRONT AND HONEST ABOUT THE INFORMATION PROVIDED)Se sono "Webmasters onesti o meno" ,non ha nessuna importanza nel contesto online, perche' la vera differenza la fornisce il livello dell'imbecillita' ,in quanto l'onesta' è verificata al 100%:) Non è possibile "applicare nessuna scorciatoia" per avere i valori reali e quindi o si è onesti in maniera naturale, oppure si è abbastanza intelligenti per comprendere che "è molto meglio essere onesti":) Gli imbecilli del "Deceive Users" non lo capiscono e quindi,oltre ad essere disonesti ,debbono anche pagare altri imbecilli come loro ,per trovare soluzioni del tutto inesistenti,rispetto ai loro contenuti:)L'esempio è nell'immagine stessa unita al Business e la migliore evidenza,è nel Gibberish Content:)Esistono diverse pubblicazioni in cui è presente e una di esse è AUG 2020,sistemata qui
I passaggi dedicati al Gibberish Content hanno dimensioni notevoli e per unirli ai contenuti di questa pubblicazione,è sufficente la sintesi stessa del suo nome e cioe' "Ginnerish" ha come riferimento "contenuti non comprensibili" fino ad arrivare al NonSense:)La Non Comprensione dei contenuti è quasi sempre unita alla Struttura Data e per paradosso,si raggiunge "la migliore comprensione",tramite la sua assenza:) (l'unico problema deriva dal fatto che non esistera' nessun miglioramento reale,perche' i contenuti saranno eliminati completamente:)E' perfetta anche in questa posizione ,sopratutto per l'unione con le categorie del Business:)
Anche i Gibbarish Content ,possono essere presenti nei CMS (Content Management Systems) e nel loro Caso ,qualsiasi unione,diventa facile,perche'esistono i costi del servizio , ed è sufficente applicarli ai contenuti che seguiranno,per comprendere l'importanza di tutti i passaggi precedenti:) (categorie Business;Struttura Data ;Snippet)Il nesso con la pubblicazione protagonista di questo 72° RF è molto semplice,perche' nasce dai suoi contenuti diretti,attraverso la Quality di Bing (NOV 2016) e poi esistono anche gli sviluppi dopo 4 anni e sono i Content sistemati nelle categorie Businnes e per renderli operativi è indispensabile che esista l'opposto,rispetto ai passaggi precedenti. (deve essere presente la struttura data e deve essere assente il Gibberish Content:).L'unica presenza consentita è il Long Standing Webmasters Guidelines e solo da ESSA deriva l'iNDEX piu' recente, per key Unit Quality Bing:)
La migliore sintesi dei passaggi precedenti è nei contenuti dell'immagineIn realta' le categorie non si possono scegliere ,perche' occorrono i Content specifici per averle e naturalmente, iniziano dalla loro unicita':) Se dovessero essere aggiunte o modificate delle categorie,occorre prima verificarle "in maniera molto accurata" ,attraverso la Key Metrics piu' importante al mondo e a differenza degli oceani di tools ,conosce il contesto globale,come nessun altro!:)Gli oceani di tools non possono farlo,perche' non conoscono nulla e tantomeno sono capaci di unire i valori dei dati ed è possibile verificarli in tanti modi e quello del Keywords Difficulty precedente,diventa un ottimo esempio di verifica:)
Questa sezione deriva dalle General Guidelines e il riferimento specifico è proprio il Business.Non esiste nessuna possibilita' di Equivoco:)I responsabili dei contenuti per il Business ,non sono gli autori diretti,ma coloro che gestiscono il dominio (sono le organization ed esistono gli esempi di IBM ;Facebook ;Wikipedia).E' una posizione logica e nasce da un fatto altrettanto logico e cioe' le "organizzazioni indicate" ,sono formate in realta' da 1 solo dominio e quindi il responsabile è unico.
Questa posizione è solo un esempio e altrettanto lo è il numero di organizzazioni ,perche' è in realta' elevatissimo e al suo interno è possibile sistemare tutti gli High Learning ,perche' sono formati dallo stesso metodo e cioe' esiste solo 1 responsabile del dominio e tantissimi autori.All'apparenza questa posizione "potrebbe sembrare un vantaggio" ,perche' esiste 1 solo responsabile,mentre nella realta' ,il metodo di avere tanti autori in 1 solo dominio,rende molto facile arrivare al Low Quality e la posizione diventera' pessima anche "per le organizzazioni" (il motivo è molto semplice,perche' gli autori non sono tutti uguali e coloro che hanno contenuti in Low,danneggiano anche quelli in High,perche' le posizioni sono all'interno di 1 solo dominio o "organizzazione":)questo è il motivo per cui è facile arrivare ai Low Quality "per 1 organizzazione o dominio"
Ho utilizzato "PRODUCT" unito al Business e quindi ai termini utilizzati per creare i contenuti e il loro dato finale sono sempre gli MC:)Quindi avere tanti autori e 1 solo responsabile,puo essere positivo "per i dati dei rilevamenti di base",pero' non hanno applicazioni reali nel contesto online,perche' gli autori in Low,elidono quelli in High ,ad iniziare dalla difficolta' di creare Main Content e poi occorre vedere se esistono anche dei loro Copied e solo al termine si hanno le rilevanze e il riferimento è 1 solo dominio o organizzazione e gli eventuali valori del contesto globale,arrivano solo dopo!:)La soluzione è molto semplice,perche' se esistono autori validi,è sufficente creare 1 dominio in proprio e separarsi dalle "organizzazioni":) (se dovessero avere pensieri opposti,semplicemente non possono essere dei grandi autori,perche' sono proprio imbecilli di base:) Questa posizione è valida per il Business e qualsiasi altro servizio di Google.
Semplicemente occorre non bloccare le operazioni dei Crawling Process (sono i vari NoFollow links IN ; i Disallow ;gli Internal Links OUT) ,perche' senza di essi non esistera' nessun Main Content di sicuro e i valori non esisteranno nemmeno in futuro,perche' vengono selezionate anche le posizioni negative ,ammesso che esista un altro Crawling Process in futuro:) (lo potranno avere per altri contenuti,tranne quelli bloccati in precedenza).
Quindi nel Contesto Online ,non esiste "l'onesta condizionata" ,ma puo essere presente solo al 100% e quindi è una grande rivoluzione rispetto al contesto tradizionale,perche' tutti i valori sono certificati in Long Time e quindi non puo esistere nemmeno "un piccolo dubbio":) Se fosse presente,semplicemente vengono eliminati i contenuti e quindi o si è onesti in maniera naturale,oppure si diventa onesti per intelligenza ,per la semplice ragione che non esiste nessuna alternativa all'onesta!:)
Iniziano dal collegamento precedente del Brain Stone e altri sono in OCT 2020 ,uniti alla posizione dell'Organic. E' in pratica la stessa evidenziata sopra,ed esiste solo la differenza delle descrizioni e iniziano dal riferimento per "Featured Snippet" e sono identici a tutti gli alttri,pero' cambia la posizione e diventa la prima di qualsiasi ricerca (è il Box in Highlights sistemato nell'evidenza).
E' fantastica anche la seconda posizione,solo rispetto alle evidenze:)
Information Quoted form third part of website
Questi 7 termini potrebbero essere sistemati ovunque e formano la vera differenza con tutti gli oceani di tools,compresi quelli che hanno anche il possesso dei codici :)
Solo attraverso loro (i 7 termini) è possibile avere qualsiasi informazioni sui valori reali dei dati e iniziano con la domanda piu' pertinente da rivolgere a un Engine:)
Le "Information Quoted" sono equivalenti al Copied dei Main Content per i contenuti interni ai domini e nel Contesto Globale ,sono valide le stesse informazioni:sono molto semplici e iniziano dalle Guidelines e i suoi fattori "non sono le solite centinaia descritte nei contenuti seo",ma ne sono poche unita' e sono quelle del natural Contest:) Se viene superata questa posizione,ne diventano in realta' migliaia,perche' ogni termine delle Guidelines puo essere considerato 1 fattore (dopo l'Update di OCT 14 2020,ne sono oltre 60000 i possibili fattori!:)Le Quoted sono lo strumento fornito dagli Engine per comprendere tutto il percorso fatto ,attraverso i "Fattori Noti ; Pubblici e sopratutto Reali" e le informazioni che forniscono ,derivano dalle Rilevanze dopo i Match dei termini e il loro High è assai diverso,rispetto al Contesto tradizionale,perche' non è possibile "millantare nemmeno 1 virgola" ,perche' i dati derivano da valori noti al 100%:)Questo metodo è valido per il contesto globale e naturalmente,anche per i contenuti interni ai domini e il senso di "Third Part of Website" per le Information Quoted ha un senso semplicissimo e sono le rilevanze dopo i Match dei termini e formano l'organico interno e cioe' i Main Content,compresi i suoi Copied:) Solo ed esclusivamente da questa posizione,si passa alle Information Quoted del contesto globale e dopo tutte le operazioni arriva l'INDEX:)Quest'immagine deriva da OCT 2020Le SERP Features sono proprio gli Snippet dei Box in Highlights e il percorso è quello indicato sopra dell'Organic e la differenza con gli Sponsored, deriva dal fatto che non esiste nessun Paid per avere alte rilevanze ,sia per l'Organic o Natural Search e per le Serp Features e quindi i contenuti presenti,possono arrivare in High, solo per meriti propri!:)
questa è una fantastica domanda:)Indirettamente è una sintesi perfetta per "Don't Deceive Your Users":)I Featured Snippet offrono un grandissimo vantaggio e quindi tutti vorrebbero averlo e non esiste nessuna possibilita' "di selezionare in maniera autonoma" questo privilegio:)E' fantastico anche il periodo dell'Engine: dopo aver negato qualsiasi possibilita' di selezionare i contenuti ,ha concluso il periodo in maniera onesta,senza illudere "i poveri webmasters":) Cioe' non perdete tempo a selezionare Mark inesistenti,per i Fetured Snippet e qualsiasi altra posizione ,ma preoccupatevi solo di "Elevates It" e cioe' di fare contenuti migliori:) Il contesto originale del passaggio deriva dal 2° RF 8D
Il contesto originale deriva dal 2° RF 8D
Da essa è nato l'arco temporale per la presenza delle Sitemap (NOV 2016 gia' esistevano) e i contenuti dell'immagine forniscono altre importanti informazioni:)La prima è quella piu' semplice e cioe' Google non seleziona tutti gli URL presenti in 1 Sitemap e la sua presenza ,viene verificata solo 1 volta ,ed è inutile inviare Ping di segnalazioni,perche' verranno completamente ignorati.Altri Ignore Totali sono applicati a 2 presenze nei codici: <priority> e <changefreq> e in teoria possono essere sistemati nei codici delle pubblicazioni,pero' non esiste nessun Input a loro riguardo,tranne l'Ignore Totale:) (nessun webmasters stabilisce qual'è la priorita' e tantomeno fornisce i tempi per il Crawling Process:)Esiste un altro codice da poter unire alle Sitemap ,ed ha una posizione fantastica,perche' a sua volta è unito al re-crawling e sono le richieste di revisione,per alcuni contenuti.E' gia' molto difficile che vengano accettate ,perche' l'onesta dei webmasters "ha una scarsa fiducia" e comunque,alcune possibilita' esistono e chi volesse fare dei re-crawling,le migliori chance per avere la revisione dei contenuti,si ha inviando la propria Sitemap e naturalmente deve essere gia' esistente nell'arco temporale unito ai contenuti da revisionare e questo è il senso di <lastmod> e occorre fare attenzione ai dati inseriti,perche' se risultano falsi ,la lettura dei codici della revisione termina immediatamente,ed è sicuro che non esistera' nessun altra in futuro:)Questa posizione,rende ragionevole anche l'onesta' al 100% del contesto online (solo per gli Engines ovviamente :) ,perche' il codice <lastmod>,per essere contestato ,deve avere anche la conoscenza delle posizioni precedenti dei contenuti ,comprese le sue date.Quindi chi dichiara il falso ,attraverso il <lastmod> delle Sitemap,durante una revisione dei contenuti,è solo un imbecille e non ha nulla in comune con l'onesta:) (il suo valore è sempre il 100% e si raggiunge con l'onesta' effettiva oppure con il minimo d'intelligenza e cioe' non conviene proprio essere disonesti nel contesto online:)
Questa è la posizione meno citata dei codici,pero' è la piu' importante ,perche' qualsiasi verifica deve avere gli "End Of Code" e cioe' debbono essere noti tutti i contenuti e il codice <lastmod> citato sopra,deve avere queste referenze,altrimenti la richiesta di revisione,se fosse accettata,termina subito!:)